Brandon Mangold, Solutions Architect
What I wanted to discuss today was the fundamentals of good network design. There is a saying that designing a complicated network is simple but designing a simple network is complicated.
It has been my observation that a strong design discipline as well as lacking documentation skills are the biggest downfall of IT staffs in general. Documentation is often a fundamental problem of motivation and priority but there are certainly documentation skills that can help.
But first we want to consider what a network is fundamentally? Is it a collection of links, protocols and devices that move packets? No, it is not. Fundamentally, it is a mechanism or an infrastructure, built to carry application traffic that enables a business or entity to function. We must have the proper perspective when coming into a network design situation to begin with. At the end of the day, in an enterprise or service provider scenario, we need to “enable the business”. Fundamentally, the network should enable application communication in a reliable and predictable way, with as little overhead and oversight as possible.
What this means: the FIRST step to designing a network is to think about and define the PURPOSE of the network. (Requirements, baseline, etc.)

That’s no network… it’s a system for application enablement!
Next to consider are the fundamental network requirements. Generally, the first major consideration is to reliably enable the business to achieve its goals, thus the network must be reliable.
Determining the level of reliability necessary is the next logical step in the design process. What constitutes a failure? Can the business, or certain aspects of the business, survive a short term outage? Are there business resiliency protocols built in to protect against general technology failure or is the business or an aspect of the business totally dependent on technology availability? Again, thinking in terms of the network as an infrastructure built to carry application traffic that enables the business, one should begin to define the applications and their level of criticality to the business. We will not delve into too many details but as a general example, in most enterprises a short email outage may result in only discomfort, in other businesses it may be more critical. On the other hand, in high frequency trading applications, a relatively short change in the network that disrupts even the consistency of the network can be extremely damaging. In this instance, zero packet drops with a minor increase in network jitter can constitute a network failure.
In building a reliable network, it is important to understand that there is a difference between resiliency, reliability and redundancy. Redundancy is a mechanism that MAY achieve a measure of resiliency but resiliency may not require redundancy and redundancy may not equate to resiliency. On the other hand, increasing resiliency by adding redundancy doesn’t necessarily increase reliability. For example, if a high speed multi-hop link is used to backup a high speed direct link, the additional latency and jitter introduced by the backup link may cause applications to perform poorly or even to fail. In such an instance the network has essentially failed to enable the applications. The network has failed to provide reliability.
Note: a good rule of thumb, where resiliency is critical, is that removing single points of failure by adding two way redundancy is relatively efficient. Trying to remove dual points of failure often comes with greatly diminishing returns that must be weighed carefully.
What this means: the SECOND step is to design a reliable network by considering what constitutes a ‘network failure’ from the standpoint of the applications.
What that in mind, we move to the next major tenant of designing networks: manageability. It is inevitable that networks will experience change over time. Building a manageable network is often an exercise in simplicity. A simple test to determine if a network is manageable is the “2am test”. Consider that it is Friday night and you are awoken by a phone call due to a network failure. You are called upon to troubleshoot a segment of the network that you have not touched in over 3 years. Bleary eyed and exhausted you log into a network management console and review the current configuration of the devices in question. Will you be able to clearly and easily understand the relationship between the route advertisements, route-filters, ACLs, route-maps, QoS and traffic engineering? How much time will be necessary to decipher the original intent of the configuration and how it may have been modified over the years? Five minutes, fifteen minutes, 2 hours? All precious time when trying to enable the magical reliable “five nines” network.
Beyond the complexity of the network is the concept of documentation. As stated at the onset, the two primary failings in IT organizations that I see today are design discipline and documentation skills. A manageable network is one that is easy to understand. Good documentation is critical to being able to quickly learn and troubleshoot a network. We will not extensively cover network documentation in this blog post but there are numerous sources of good information that can help you but suffice it to say that generating a network baseline (utilization, availability, etc) and good topology, addressing and application flow diagrams are at the core of good documentation. Consider the “2am test” and the effects of a well documented network vs a poorly documented network on the results.
What this means: the THIRD step is designing a manageable network. Take the “2am test” and see how you can reduce the learning curve through simplification and documentation.
The last major consideration when beginning the design process is to consider how the business or organization may change or grow as time progresses. The goal of any business is growth. The network should be ready to grow with both technology and business. Scaleability is not just related to the ability to grow nor is it necessarily predicated on the size of the network. A small network may be unstable and require major rework to adapt to new applications whereas a large network may be very stable and require little change to adapt to new application requirements or technologies.
There is a fine balance between reliability, scaleability and manageability. These are the primary goals a good network designer should aspire to achieve.
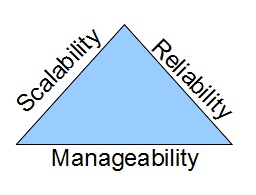
Generally, the more manageable the network the more scaleable it becomes. Conversely, adding reliability mechanisms like redundancy can decrease scale and manageability in a linear fashion. Consider, that in order to remove any single point of failure a full redundancy of all systems doubles the system in all aspects. In order to remove double points of failure it is often necessary to add a third layer of redundancy The increase in convergence time, management overhead and scaling limitations may or may not outweigh the benefits of resiliency in these scenarios. Adding further redundancy may likely be a net loss to the resiliency of the system.
What this means: the FOURTH step is designing a scaleable network by carefully weighing the relationships between redundancy and resiliency in relation to what constitutes reliability of application performance.
In summary: Fundamental to designing a network is the fine balance of the reliability, scalability and manageability of the system for the purpose of enabling applications that allow a business or entity to function.
Personally, I am a big fan of the KISS (Keep It Simple Stupid) principal. Simplicity in network design is key but just as important is the second S in KISS … stupid. The more you learn the more you know what you don’t know. Since attaining my CCIE just over a year ago I have learned more and more just how clueless I really am. I think it is equally important for us to be humble in admitting that we really are ‘stupid’ in relation to the vast volumes of information available for us to consume. With that in mind I leave you with this well known quote:
“NEVER MEMORIZE SOMETHING THAT YOU CAN LOOK UP.”
NOTE: This blog post was inspired by my musings and study of the book: Optimal Routing Design by Russ White, Alvaro Retana and Don Slice. This blog post is essentially a very quick summary of the basic tenants of the book with a little bit of my real world experience sprinkled in.
http://www.ciscopress.com/store/optimal-routing-design-9781587051876